当你【调戏】一个RAG系统时,一个正经的RAG会怎么想
推荐语:来看一下大模型热潮的三个主攻方向 1、知识库问答 2、Chatbot(比如各类聊天机器人) 3、Agents(AI助手)
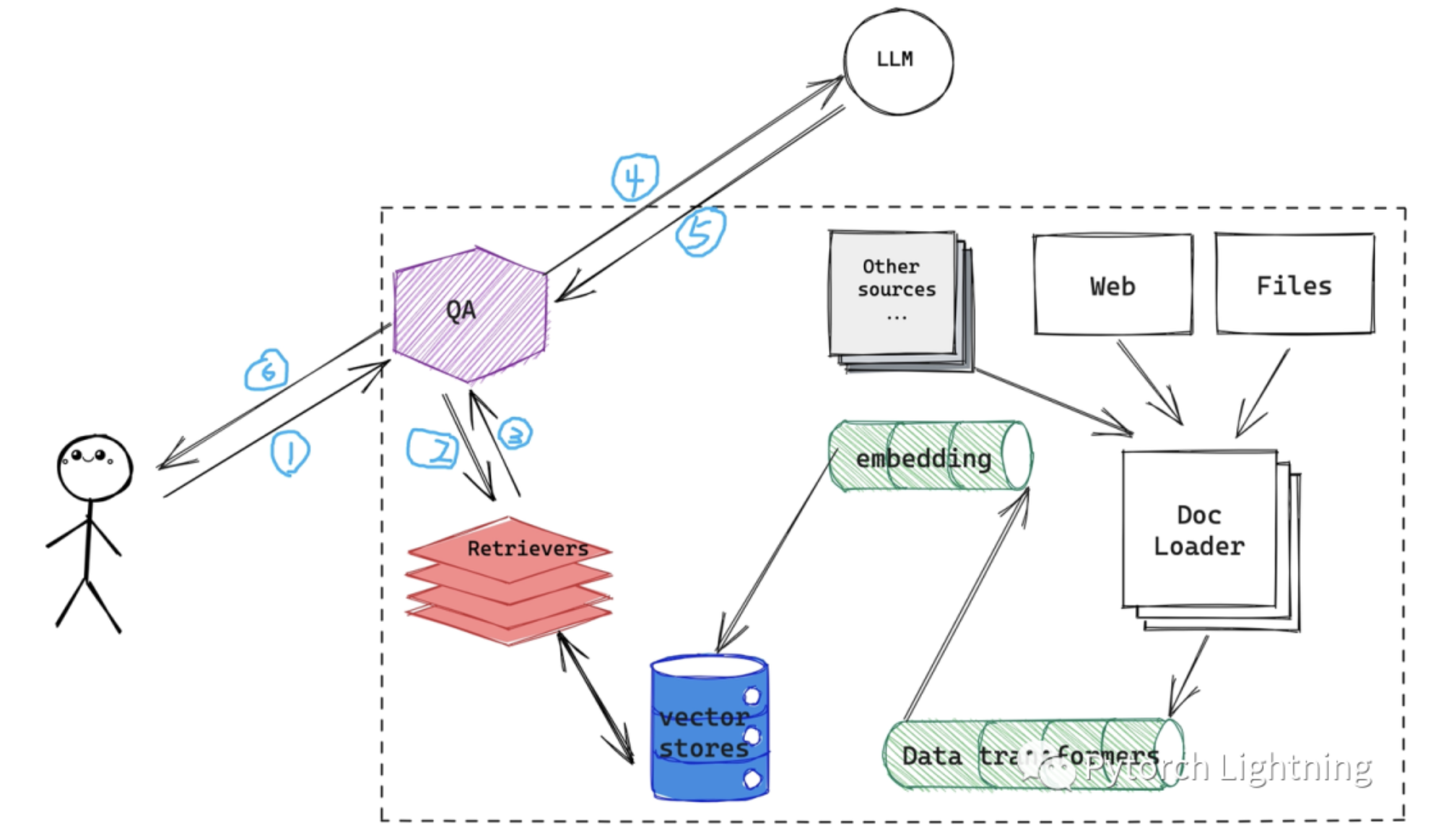
图一:一个「经典」的 RAG 系统数据流转
我们看这张图里面,一个「经典」(这里值得时距离当前三周以前的时间...)的 RAG 系统会假设你是一个正经的用户,会按照套路正经的使用系统 1、2、3、4、5、6 步走下来。
但大家都清楚,一旦你的代码放到生产环境中,啥用户都能碰到,就是碰不到几个「正经」用户,你无法让用户按照你设定的套路问问题,比如在一个
讨论毕加索同志作品、生平、创作风格的上下文里面,很多用户上来问的问题却是,“你好,今年你几岁?“...
“今年你几岁?” 这种问题当然适合直接扔给神奇的 ChatGPT 直接回答,但正如上图,一个「传统」的 RAG 其实要先把用户的输入通过 2、3 两
步,放到自有的向量数据库里面走一遍,然后把拼接出来的结果通过 4 再扔给 GPT 们来寻求比较流畅的答案的。那么有没有办法可以直接预判用户的预判,在向量搜索之前先确认一下用户是要「正经使用」还是要闲聊的?当然是可以的:
正经使用:1、2、3、4、5、6
闲聊:1、4、5、6 (在 LangChain 里面去掉 2、3 其实就是去掉上一篇关于 embedding 创建、更新的部分,也就是「 from langchain.indexes import index 」这个 index )
脑洞在开的大一些的话你会发现,上图中虚线框出来的部分,除了「QA」之外就是一个完整的 RAG,设想一下如果用户想要的不是 RAG 系统里面外挂的内容,而是需要借助外挂的搜索引擎获取最新的资讯,或者外部的天气 APIs、交易 APIs 获取更为实时的信息的话该怎么办?是不是就要请出 LangChain 里面另外两类组件,Chain 和 Agent 了(区别在于两者逻辑的实现方式,前者由用户写死在代码里,后者控制权上缴给大模型听
从大模型的调度)?
来看一下 LangChain 的同学们准备如何解决这个问题的,他们认为近半年来大模型热潮主要体现在:
- 外挂知识库的大模型,也就是 RAG 系统,代表应用是 chatpdf 类的 app
- Chatbot Interface,在上一波智能音箱热潮里面,大家一般把这个 interface 叫做 CUI(Conversational User Interface),说到底就是通过对话的方式获取信息,这波的代表应用毫无疑问是 (https://chat.openai.com/) ChatGPT,本来就是本设计成一个收集用户反馈投喂 OpenAI 内部 AGI 产品的工具,没想到不小心火成了第四次工业革命
- Agents,上面也提到了,LangChain 里面有两个概念很类似,Chain 和 Agent ,当然后者得到了业界更多的热捧,来自 OpenAI 的大神 Andrej Karpathy 更是在一次演讲中直接用了 「Why you should work on AI AGENTS」为题目,但我们要稍微冷静一点看到,正因为 Agent 和 Chain 不同,前者是由大模型来根据不同的任务拆解成不同的 task 队列,每个 task 队列就是一排 Agent 在执行任务,这样做的好处固然很明显,很多边边脚脚的场景下会给用户带来惊喜,但也由于同样的原因,开发者无法预测所有的场景下 Agents 的表现,这给监管严格的环境下大规模的应用部署带来了很大的潜在风险。
把上面三个趋势结合起来,做成一个既可以在外挂数据里面「正经」回答问题;又能接的住「不正经」用户的闲聊挑拨;还能,根据用户提出的新问题,通过大模型自动通过 react 或者 openai-functions 的方式,动态生成一群小 Agents 帮用户完成新问题。这种「既要、又要、还要」通通满足的产品,就问你想不想要?
在正式上代码之前,还是要强调这个思路里面,最最重要的一点:
本思路之所以可以「大概判断」用户是否在闲聊,最主要的原因是在原先「chat_history」也就是聊天上下文里面,带上了大模型和大模型用到的工具之间的调用交互信息,通过让大模型看到通过 react 或者 openai-functions 调用外部工具的历史信息学习到了如何使用工具的知识,进而在接下来与用户的对话中可以判断是否去调用外挂工具,是否去检索外挂数据。既然在上下文里面添加了跟外部工具调用的历史信息,那么可以想象的,对大模型可以接受的每次调用的窗口长度提出了更高的要求,比如 chatgpt-3.5 只有 4k,后来加到了 16k,估计以后会更大
正式上代码,LangChain 的实现位置在这里:
from langchain.agents.agent_toolkits import create_conversational_retrieval_agent
根据上面的叙述,这个思路其实概括起来就是需要一个强大的大模型 + 一堆封装好的外挂工具,大模型一般就是 chatgpt 了;CUI 的交互方式和 RAG 创建沿用之前的内容;工具的引入也有封装好的代码:
from langchain.agents.agent_toolkits import create_retriever_tool
创建一个 retrieval 来完成外挂数据源检索的问题:
# 前面代码不贴出来这地方了,用 FAISS、ANNOY、ES、Chroma、weaviate 都可以
retriever = db.as_retriever()
创建一个 tools 数组,用到多少外挂工具就实例化多少:
tool = create_retriever_tool(
retriever,
"search_state_of_union", # tool name
"Searches and returns documents regarding the state-of-the-union." # description of tool
)
tools = [tool]
这个 create_retriever_tool 简单看一下它要的参数:
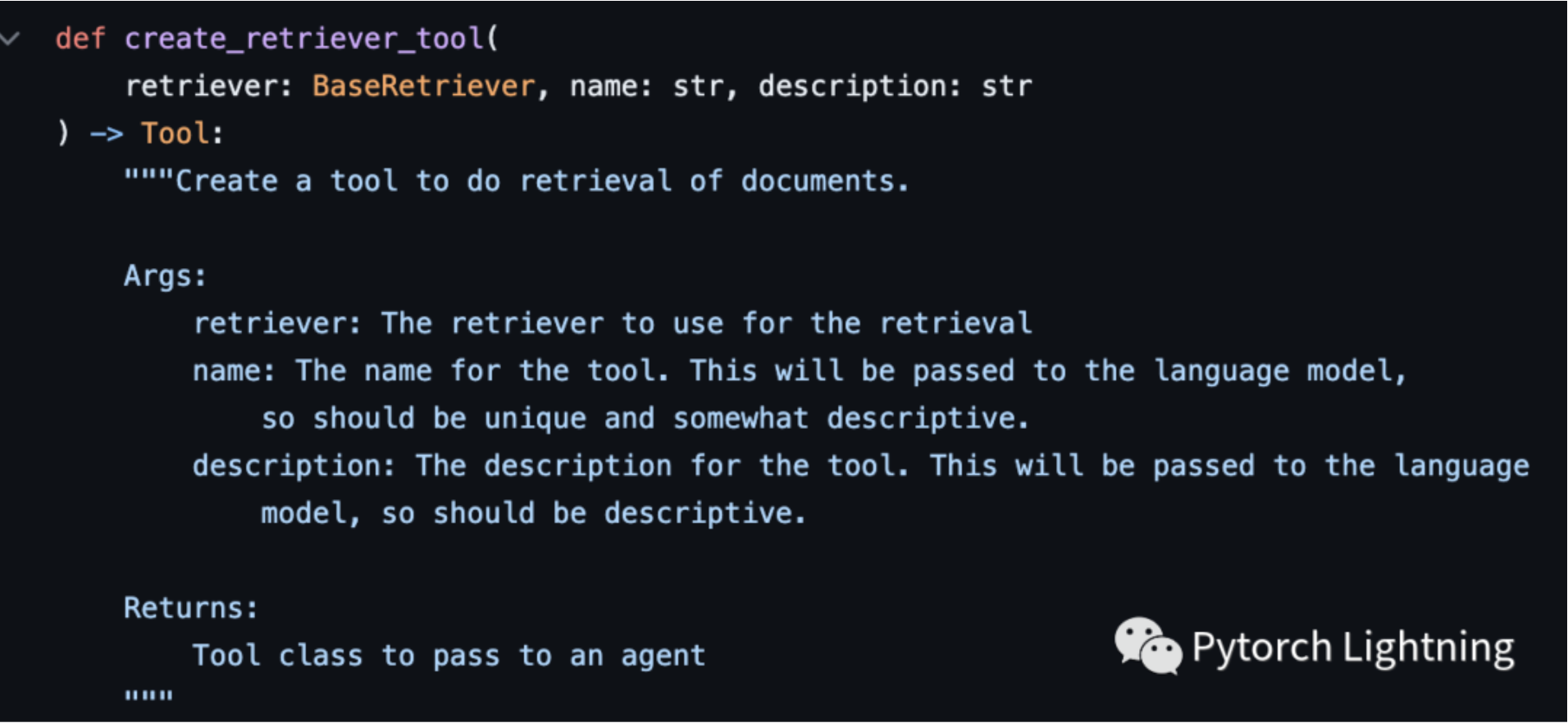
图二:create_retriever_tool 的参数说明
可以看到除了 retriever 之外,还需要定义一个工具名称和一个说明。
接下来接入大模型,把 tools 、llm、RAG 组装在一起组成上面提到的既要、又要、还要:
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature = 0) # 这里 temperature 设置成 0,标识让大模型尽可能的不要自由发挥
# 组成「既要、又要、还要」
# verbose 设置成 True,输出大模型的交互过程,方便理解
agent_executor = create_conversational_retrieval_agent(llm, tools, verbose=True)
# chitchat 或者调戏一下试试
result = agent_executor({"input": "hi, im bob"})
由于打开了 verbose 开关,我们可以看到输出如下,注意,虽然我们给大模型外挂了数据源,外挂了工具集,但这种简单的调戏/打招呼是由大模型
直接回复的,回复路径是图一中的:1、4、5、6,既不会走 RAG 检索;也不会调用外挂工具。

图三:chitchat 交互
继续闲聊的话依然不会走 RAG 检索,也不会调用外挂工具,还会记得上下文:
result = agent_executor({"input": "whats my name?"})

图四:chitchat 交互 2
如果用户问到外挂数据集种的内容就会触发 RAG 检索;如果用户的问题里面涉及到了需要调用 tools 外挂工具就会自动调用外部工具完成任务并返回结果告知用户。
这个思路是不是让人感觉打开了新的视界,瞬间产生想拍桌子单干的冲动?别着急,看完总结再说。
总结一下:
这个 create_conversational_retrieval_agent 是 8 月 3 号才加进来的,所以,还是那句话,大模型领域发展秒新时异,在拍桌子之前想好是否能适应这么快的节奏非常重要
再说一遍,在 LangChain 的视角里,解决这个既能闲聊天应付调戏、又能正式通过 RAG 正经回复、还能调用外部工具完成一些边缘场景任务的「既要、又要、还要」问题的,说到底是一个 Agent,所谓 Agent 不同与 Chain,后者是用户自己写死执行逻辑解决问题,Agent 是由大模型学习到领域知识后,通过 react 或者 openai-functions 等方式来针对问题做 map-reduce
接下来想更仔细的看一下 RAG 的场景,上线过 RAG 的同学肯定理解到这个痛点:基于向量比较的检索精度不够有点粗心大意;基于 ES bm25 的又过于严谨有点呆板智障,那么如果给 RAG 外挂的数据源是一个知识图谱(KG)会怎样?能否利用知识图谱 这些年在 nlp 方面的积累,在当前 RAG 系统标配 ES、标配 vector store 的情况下进化成外配 KG?